今日目的:建立一套「理解、設計、評估混沌工程」的心智地圖。
明白「為什麼」與「怎麼想」,永遠比「怎麼做」更重要。
工具只是放大器,錯誤心智 + 強力工具 = 更快撞牆。
在微服務與雲原生世界裡,系統更像一個「有機城市」:
| 現象 | 城市比喻 | 系統真相 |
|---|---|---|
| 平常順跑 | 平日離峰時段 | 資源足、依賴響應快 |
| 高峰慢半拍 | 下班車潮塞住匝道 | 下游延遲放大 queue 堆積 |
| 偶發尖刺 | 一輛拖板車卡在隧道 | 單一節點抖動、GC、IO 等尾延遲 |
| 事故擴散 | 車道封閉 → 外圍回堵 | 重試風暴 / Thread Pool 耗盡 |
| 事後才知 | 交通黑盒 | 缺乏可觀測性(只看平均值) |
傳統測試(單元 / 整合 / 壓力測試)大多在「理想條件」下進行。結果是上線後才發現:
→ 這些問題往往不在純壓測中出現。
傳統測試:假設「路況永遠晴天」
混沌工程:在「受控環境」預演下雨、塞車、事故,確認:
- 有沒有偏離「預期交通節奏」(穩態)
- 備用路線是否真的有效(降級 / fallback)
- 護欄(速限 / 紓壓機制)是否啟動如預期
與其等風暴來,不如在安全範圍內「預演」風暴,驗證系統是否具備恢復力。
| 核心概念 | 精簡說明 | 與混沌測試工具的關聯 |
|---|---|---|
| Steady State(穩態) | 系統「正常表現」的可量測指標(例:p95 < 300ms, error_rate < 1%) | 壓測基線 SLIs |
| Hypothesis(假設) | 在特定故障下注:穩態應仍維持於某範圍 | 注入延遲 + 負載時仍保持 error_rate < 2% |
| Blast Radius(爆破半徑) | 故障影響範圍,初期要小 | 精準指定目標端點 / 範圍 |
| Fault Injection(故障注入) | 刻意製造異常(Kill / Latency / Loss) | 注入網路層 / 應用層異常 |
| Guardrails(護欄) | 自動停止條件(避免誤傷) | k6 thresholds / 驗證失敗即終止 |
| Observability(可觀測性) | 沒數據就無法判斷成敗 | OTel + Prometheus / Logs / Traces |
| Automation(自動化) | 重複、標準化、Shift-left | CI 週期 + Gate |

混沌工程不是「隨機摧毀」,而是「科學實驗」——像醫生診斷。

系統健康時「可重現、可量測」的行為基線。通常會在壓測之前預熱 5–10 分鐘取得平均與分位數。
為什麼重要:沒有穩態就不知道「實驗造成了什麼影響」。
常見 SLI:
p95 latency < 300ms
error rate < 1%
RPS >= 200
CPU 使用率 < 70%
在進行特定故障注入時,系統「仍能保持穩態」的預期描述。
句型:當(某故障條件)發生時,指標在(時間範圍)內維持於(允許範圍)。
例:當對 payment-service 注入 400ms 延遲 60 秒,
需要 p95_latency < 600ms 且 error_rate < 2%。
故障實驗可影響的最大範圍(服務集合 / 流量比例 / 使用者分群 / 區域)。
核心:風險「可理解、可預期、可回收」。
自動預防實驗造成不可接受影響的限制條件(實驗熔斷器)。
error_rate > 5% 或 p99_latency > 1.2s 持續 30 秒 → 自動中止
高百分位延遲(p95、p99),代表少數「慢請求」。
為什麼重要:使用者體驗與資源連鎖效應常被尾延遲拖垮。
混沌觀察點:延遲注入後,p95 是否擴散到 upstream(上游服務也慢)。
單一路徑延遲 / 失敗 → 資源耗盡 → 拓散到其他服務。
策略:控制爆破半徑,避免初期就造成難以收斂的鏈式錯誤。
| 層級 | 示例 | 常見目的 |
|---|---|---|
| 應用層 | 錯誤回應、慢查詢、限流 | 驗證重試 / fallback / timeout |
| 通訊層 | 延遲、丟包、重排、斷線 | 驗證韌性與排隊效應 |
| 資源層 | CPU 飆高、記憶體壓迫、IO 阻塞 | 驗證 HPA / 容量預估 |
| 節點層 | Pod Kill、Node 重啟 | 驗證調度 / session handling |
| 依賴層 | 下游 API 慢、快取失效 | 驗證降級策略 |
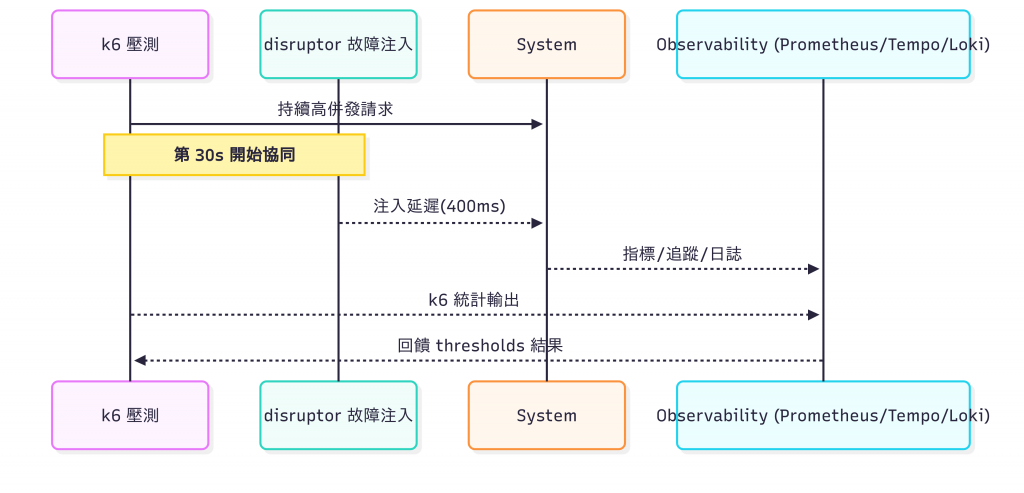
明天要介紹的
xk6-disruptor聚焦:通訊層 + 局部應用層異常。
xk6-disruptor 的價值:
| 階段 | 模式 | 工具例子 |
|---|---|---|
| Level 1 | 手動故障(kubectl delete) | 手動操作 |
| Level 2 | 專用 Chaos 平台 | Chaos Mesh / Litmus |
| Level 3 | 實驗 + 觀測整合 | 加入 OTel 指標 |
| Level 4 | 故障融入壓測 | xk6-disruptor |
| Level 5 | CI 自動化 & Gate | GitHub Actions + Threshold |
| 系統場景 | 餐廳比喻 |
|---|---|
| p95 latency 飆升 | 一位主廚手忙腳亂,出菜慢 |
| 下游服務慢 | 叫不到食材供應車 |
| 丟包 | 客人點單傳到一半消失 |
| 重試風暴 | 客人一直催菜,拖慢全部節奏 |
| 適度混沌 | 模擬某廚師離開,看流程是否重配 |
xk6-disruptor就像在「尖峰時段」刻意安排:
- 供應延遲 500ms
- 某桌點單丟 20%
再測試餐廳(系統)是否維持節奏(穩態)。
| 問題 | 混沌工程思維 | 在 xk6-disruptor 會做的 |
|---|---|---|
| 要先定什麼? | 穩態指標(SLI/SLO) | 設 p95 / error_rate thresholds |
| 要擔心什麼? | 爆破半徑 | 指定特定 host / path |
| 何時停? | 護欄條件 | error_rate > 5% → fail fast |
| 如何觀察? | Metrics + Traces | Prometheus + Tempo + Grafana |
| 怎麼疊代? | Postmortem → 改進 | 調整 timeout / retry / 併發 |
我們在設計混沌測試的實驗時,通常也會設計這些模板,來讓我們設計測試案例。
當我們在【範圍/對象】施加【故障類型 + 強度】持續【時間】,我們預期【穩態指標集合】仍維持在【允許區間】,否則視為【失敗條件 + 回收動作】。
範例:
當我們對「訂單服務單一實例」施加 400ms 平均延遲持續 20 秒,我們預期整體下單 API 的 p95 < 600ms 且錯誤率 < 2%;若錯誤率 > 5% 或 p99 > 1.2s 連續 30 秒,立即終止實驗並紀錄結果。
| 反模式 | 表現 | 改善建議 |
|---|---|---|
| 為做而做 | KPI:跑過 10 次 | 聚焦:產出改進清單 |
| 未定穩態 | 做完不知道好壞 | 先蒐集基線 |
| 一次太大 | 全域延遲 2 秒 | 切:單 API / 單實例 |
| 護欄過緊 | 實驗秒停 | 檢查基線波動 |
| 報告缺失 | 口頭:「應該沒事」 | 模板化紀錄 |
| 過度依賴工具 | 換平台歸零 | 固化語言與指標字典 |
| 面向 | 平均值盲點 | 尾延遲揭露 |
|---|---|---|
| 體驗 | 多數 OK 誤導決策 | 少數極慢 = 體驗破碎 |
| 資源 | 看不出排隊 | Queue 擴大 + 線程占用 |
| 級聯 | 只覺得「還行」 | 延遲向上游擴散 |
| 策略 | 重試似乎有效 | 重試實際拖垮更多線程 |
| 舊思維 | 新問題 |
|---|---|
| 我功能上線了 | 在壓力 + 異常下還能達成核心業務嗎? |
| 重試保證成功 | 重試是否放大延遲潮? |
| 只加資源 | 根因是否在依賴與背壓缺失? |
| 後補穩定性 | 設計階段就定降級路徑? |
真正的可靠性,不是避開風暴,而是設計出能預測與吸收風暴能量的系統。

